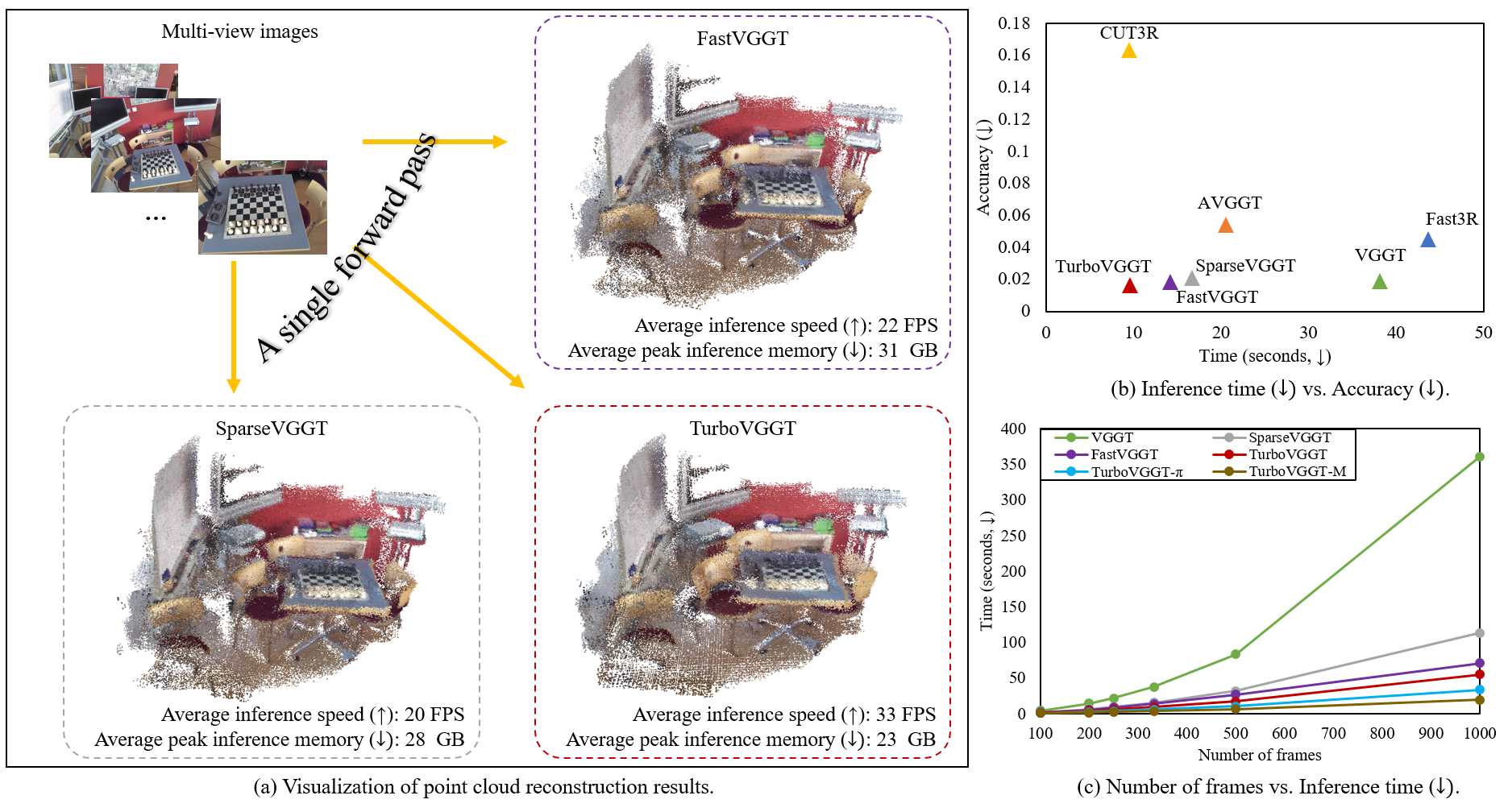
Figure 1. TurboVGGT achieves fast multi-view 3D reconstruction while maintaining competitive reconstruction quality.
Figure 1. TurboVGGT achieves fast multi-view 3D reconstruction while maintaining competitive reconstruction quality.
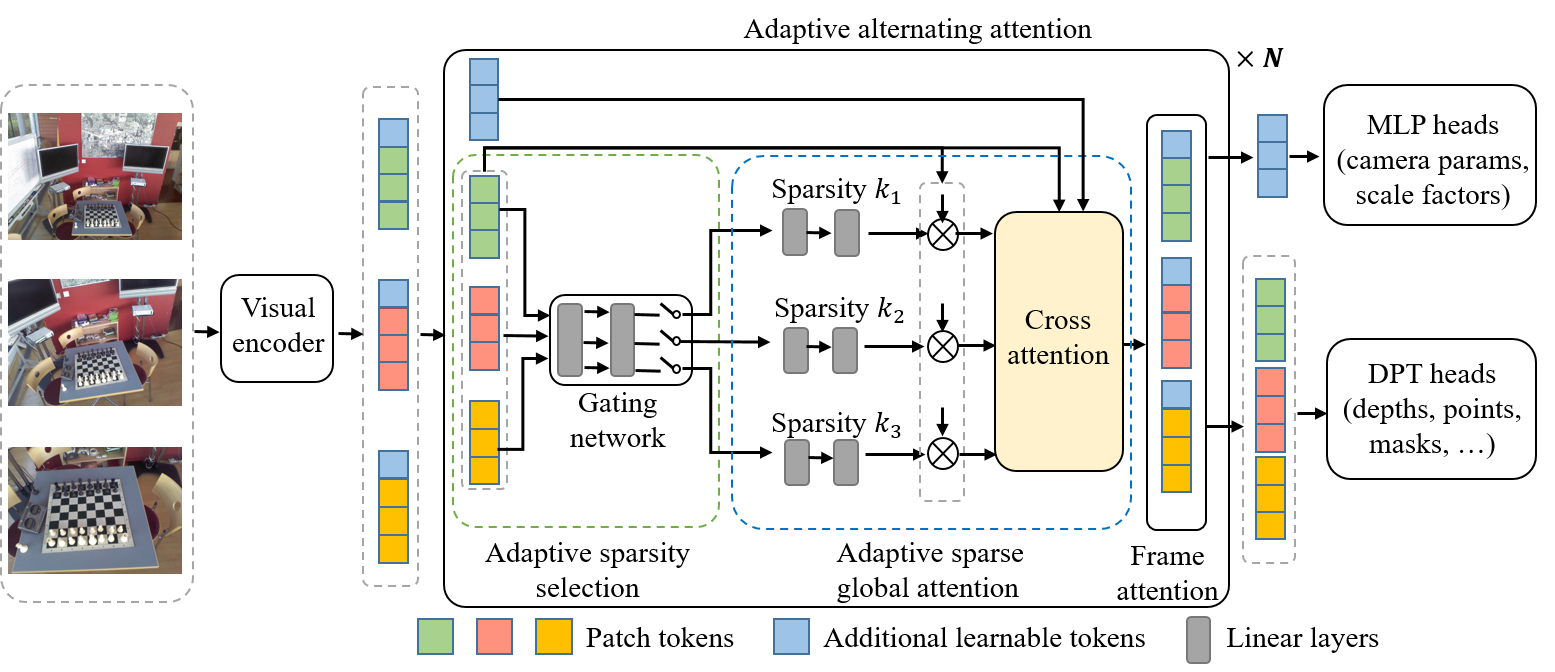
Figure 2. The overall framework of TurboVGGT.
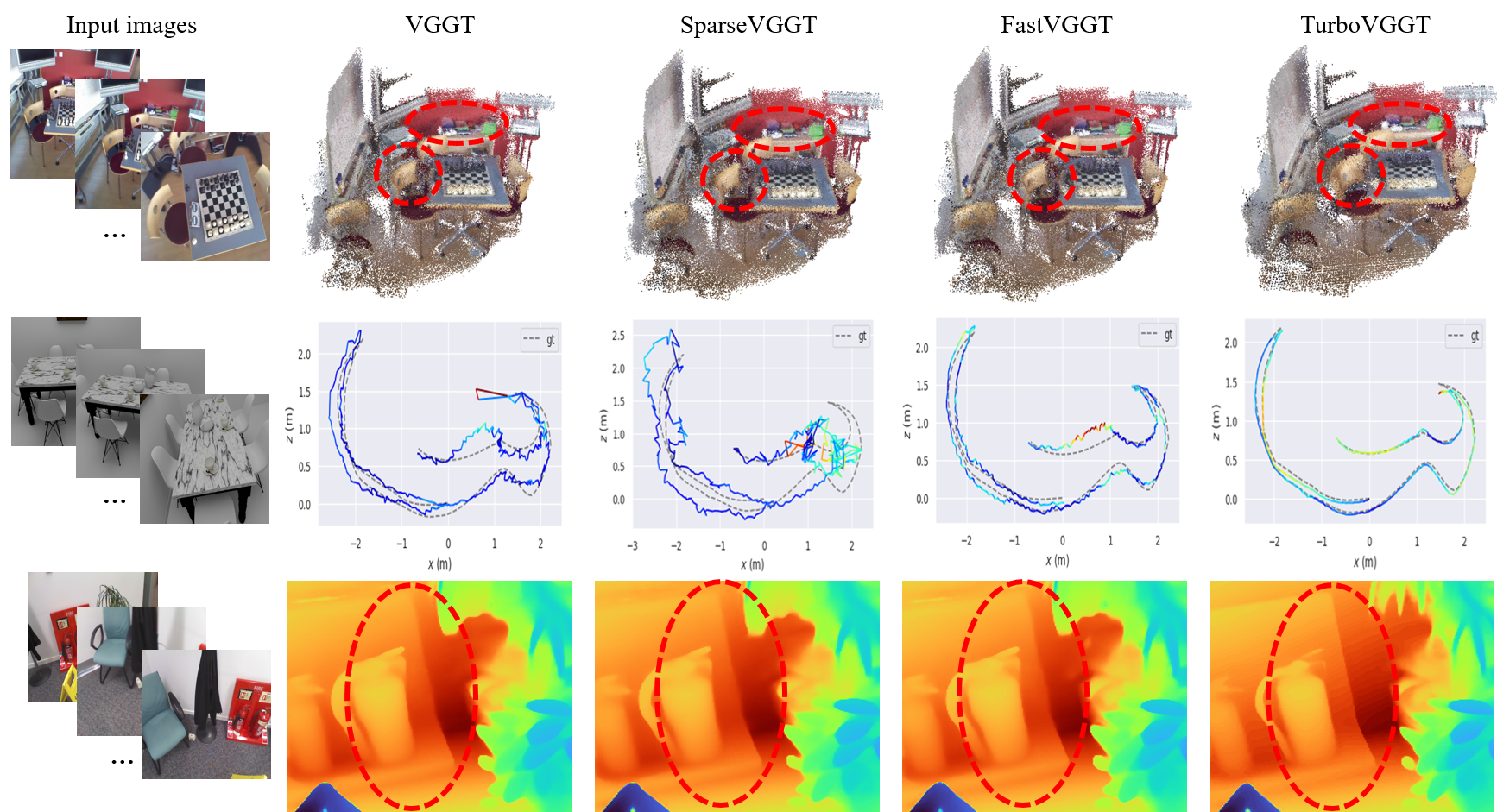
Figure 3. Qualitative comparison of point cloud reconstruction, camera pose estimation, and depth estimation.
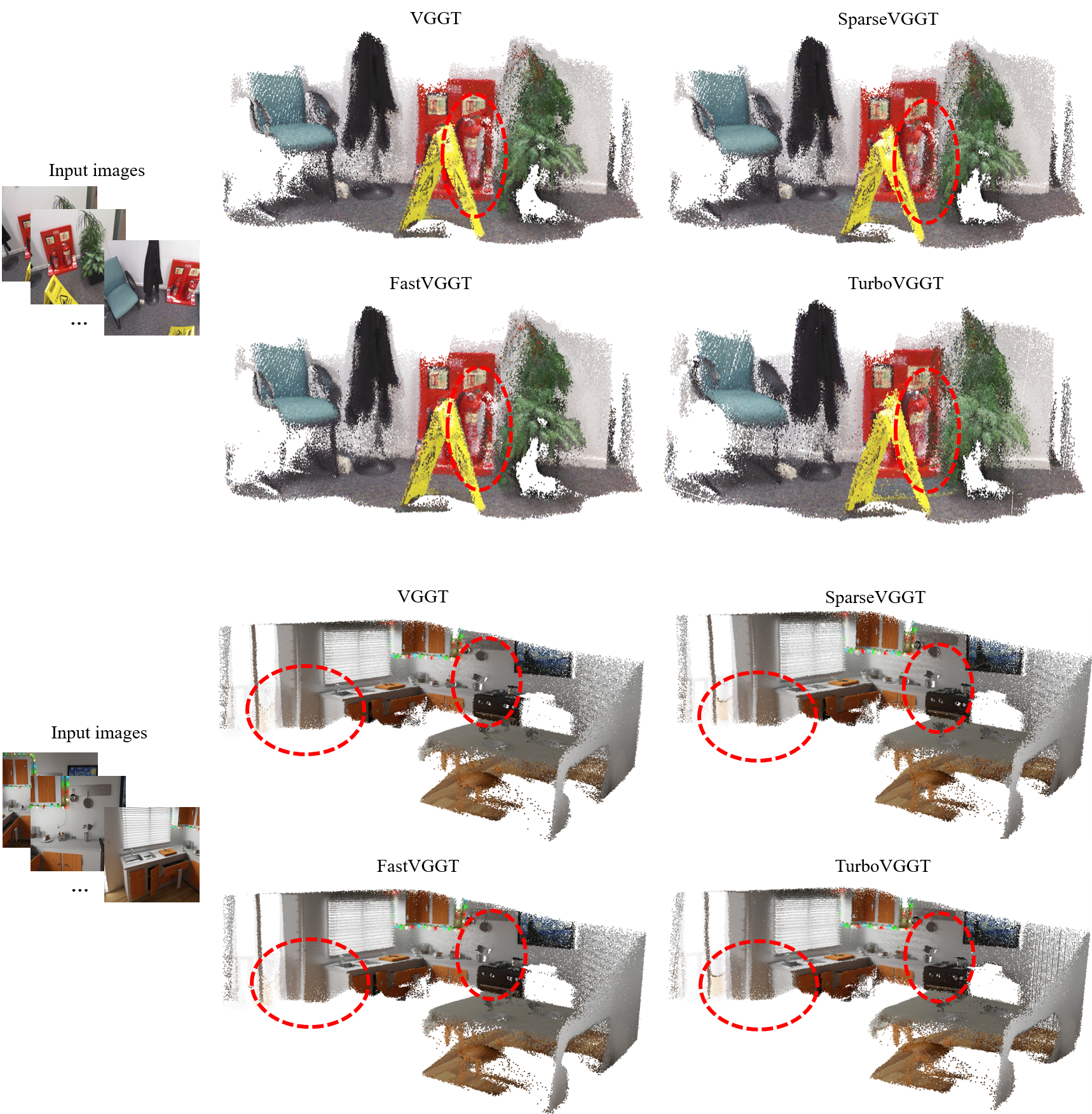
Figure 4. Qualitative results for point cloud reconstruction.
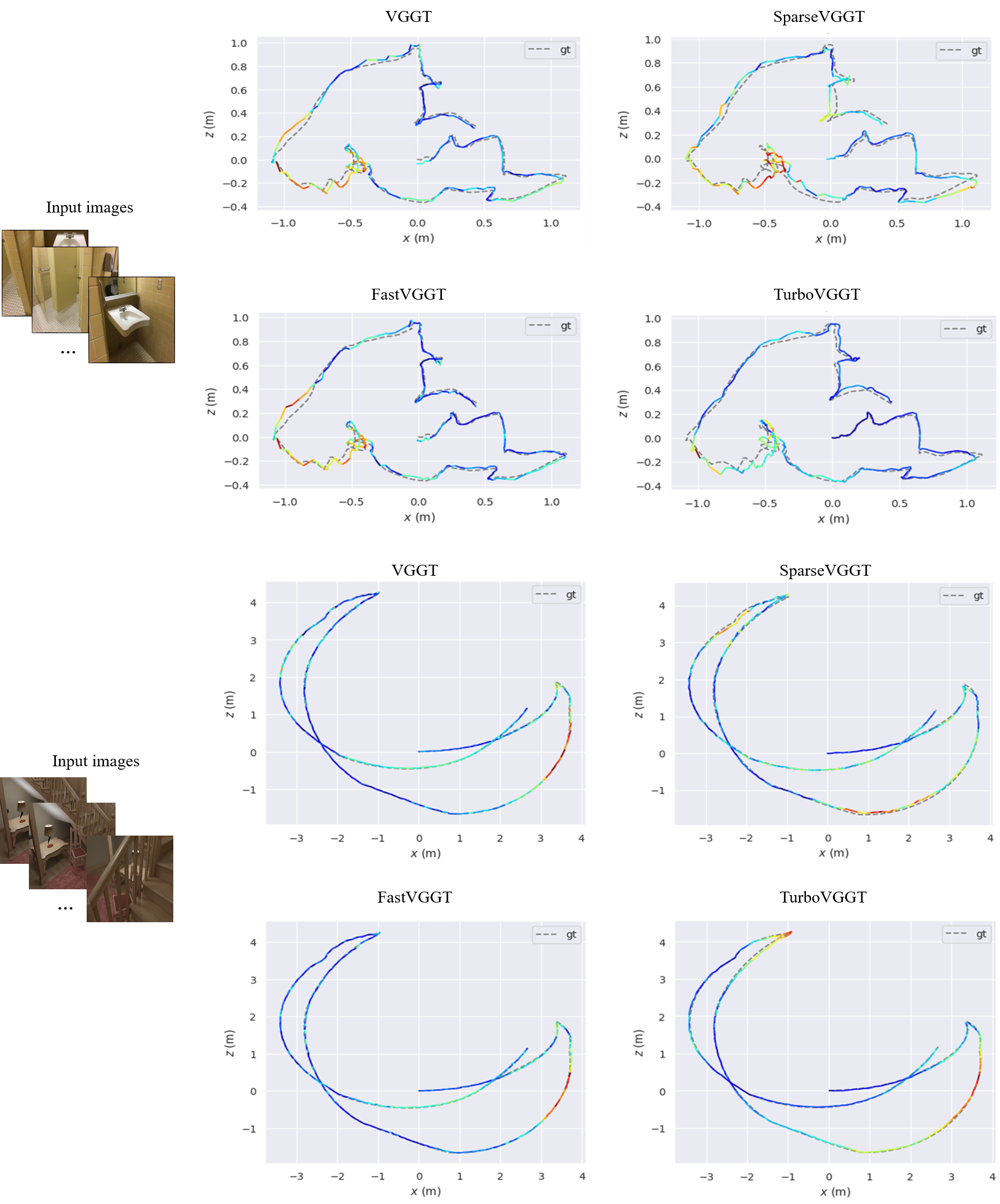
Figure 5. Qualitative results for camera pose estimation.

Figure 6. Qualitative results for depth estimation.
If you find this work useful, please cite our paper: